
Why a Good-Performing AI Model Could Actually Be a Bad Model

Image generated by DALL-E based on blog post title
Introduction
If you’re in any industry that leverages data, you’ve likely heard the buzz about how artificial intelligence and machine learning models can revolutionize your business, automate complex tasks, and provide invaluable insights. With all the hype, it’s easy to fall into the trap of thinking that a high-performing model—judged by metrics like accuracy, precision, or recall—is always a good model. After all, if it performs well, it must be learning the right things, right?
Well, not necessarily.
In this blog post, we’ll delve into the somewhat counterintuitive idea that a well-performing model can actually be a bad model. We’ll explore why a model that excels in training might fail miserably when deployed in a real-world scenario, why some models are like “smart but lazy students,” and how a model might be leveraging spurious statistical relations to give the illusion of high performance.
So, if you’re interested in not just building machine learning models but building good machine learning models, read on. This post aims to equip you with the knowledge to critically evaluate your models beyond just performance metrics.
The “Smart but Lazy Student” Analogy
We’ve all encountered them at some point in our academic journeys: the smart but lazy students who somehow manage to ace exams without appearing to put in much effort. How do they do it? Often, they’re experts at finding loopholes, shortcuts, or tricks that allow them to get good grades without truly understanding the subject matter. Interestingly, machine learning algorithms can behave in a similar manner. They are exceptionally good at optimizing for the objective function you give them, but sometimes, they do so in ways that are unexpected and undesirable.
The Objective Function: A Double-Edged Sword
In machine learning, the objective function (or loss function) is what the algorithm aims to optimize. For example, a classification model might aim to minimize the cross-entropy loss, while a regression model might aim to minimize the mean squared error. However, the algorithm doesn’t “care” how it achieves this optimization. If it finds a shortcut that allows it to minimize the loss function without capturing the true underlying patterns in the data, it will take it.
Why This is a Problem
Much like the smart but lazy student who finds a way to ace the exam without understanding the subject, a machine learning model that finds a loophole will perform well on the training data but is likely to perform poorly on new, unseen data. This is because it hasn’t actually learned the underlying patterns in the data; it’s merely found a shortcut to optimize the objective function.
An Example: Text Classification
Consider a text classification problem where you’re trying to distinguish between positive and negative reviews. If your training data contains a lot of negative reviews that happen to mention the word “terrible,” the model might learn that the presence of “terrible” is a strong indicator of a negative review. However, what happens when the model encounters a sentence like “Not terrible at all, I loved it!” in the test data? The model, taking the shortcut it learned, might incorrectly classify this as a negative review.
How to Mitigate This Issue
One way to address this problem is to use techniques that promote model interpretability, such as LIME (Local Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations). These techniques can help you understand what features the model is using to make its predictions, allowing you to spot and correct any “shortcuts” it might be taking.
In conclusion, machine learning models, much like smart but lazy students, are excellent at finding shortcuts to optimize their objective functions. While this can lead to high performance on the training data, it can also result in poor generalization to new data. In the next section, we’ll delve into another fascinating aspect of machine learning models: their ability to leverage spurious statistical relations to give the illusion of high performance.
Spurious Statistical Relations: Correlation is Not Causation
We’ve all heard the phrase “correlation is not causation,” but it’s especially crucial to remember this when working with machine learning models. Sometimes a model may perform well because it has identified a statistical relationship between features and the target variable. However, this relationship might be spurious—meaning it’s a coincidence rather than indicative of an underlying cause-and-effect relationship.
What Are Spurious Statistical Relations?
A spurious statistical relation occurs when two variables appear to be related but are actually both influenced by a third variable, or when the relationship is a mere coincidence. In such cases, the model might perform well on the training data, where the spurious relationship exists, but fail to generalize to new data where the relationship doesn’t hold.
The Danger of Spurious Relations
The primary danger of a model learning a spurious relation is that it can give the illusion of high performance. Because the model’s predictions are based on coincidental relationships in the training data, it’s likely to perform poorly when exposed to new data where those coincidental relationships don’t exist.
Example: Ice Cream Sales and Drowning Incidents
A classic example of a spurious relationship is the correlation between ice cream sales and drowning incidents. Both tend to increase during the summer and decrease during the winter. A naive analysis might suggest that ice cream sales cause an increase in drownings, which is, of course, not the case. The hidden variable here is the temperature; warm weather influences both ice cream sales and the likelihood of people going swimming, which in turn increases the risk of drowning incidents.
How to Detect and Avoid Spurious Relations
-
Domain Knowledge: Understanding the domain you’re working in can help you identify features that are unlikely to have a causal relationship with the target variable.
-
Feature Importance Analysis: Techniques like Random Forest’s feature importance or linear model coefficients can help identify which features are most influential in making predictions. If a feature seems disproportionately influential, it might be worth investigating further.
-
Statistical Tests: Conducting statistical tests for independence can help identify if the relationship between features and the target variable is likely to be spurious.
-
Cross-Validation: Using different subsets of your data for training and validation can help identify if the model is learning spurious relations. A model based on spurious relations is likely to have a significant performance drop when validated on a different subset of data.
In summary, while spurious statistical relations can give the illusion of a high-performing model, they are a pitfall that can lead to poor generalization on new data. Always remember that correlation does not imply causation, and take steps to ensure your model is learning meaningful relationships, not mere coincidences. In the next section, we’ll look at a real-world example to illustrate these concepts further.
Real-world Example: The Parkinson’s Disease Score Predictor
To bring all these abstract concepts to life, let’s consider a real-world example involving a machine learning model designed to predict Parkinson’s Disease scores. This example will illustrate how a seemingly well-performing model can actually be a bad model due to the pitfalls we’ve discussed.
The Objective
The goal of this Kaggle project was to build a model that could predict the progression of Parkinson’s Disease in patients based on protein expression measurements. A high-performing model in this context could be invaluable for healthcare providers in tailoring treatment plans for patients.
The “High-Performing” Model
Initially, many models published on Kaggle seemed promising. However, upon closer inspection, it was discovered that these models had essentially learned to distinguish between control and test patients, rather than predicting the progression of Parkinson’s Disease based on protein expression.
The Pitfall: Spurious Relations
These models had found a spurious relationship between some features and the target variable. These features were not causally related to Parkinson’s Disease but were different between the control and test groups. As a result, these models performed well on the training data but were essentially useless for their intended purpose of predicting disease severity in new patients.
The Consequences
Relying on these models in a clinical setting could have led to incorrect treatment plans and a waste of healthcare resources. This example underscores the importance of thoroughly evaluating and understanding what a machine learning model has learned.
Lessons Learned
The issue with these models was known since the beginning, but when it is not the case, the following steps can help to identify the problem.
-
Always Validate on Unseen Data: In many cases, this type of issues could only be discovered when it was tested on new, unseen data, highlighting the importance of validation.
-
Interpretability Matters: Techniques like SHAP or LIME can be used to understand what the model is actually learning, potentially flagging the issue very soon.
-
Domain Knowledge is Crucial: A healthcare expert might be able to identify the irrelevant features that a model is using, emphasizing the importance of domain knowledge in feature selection and model evaluation.
In summary, this real-world example serves as a cautionary tale of how a seemingly high-performing model can turn out to be a bad model when it learns spurious relations or fails to generalize. It’s a reminder that performance metrics are just one piece of the puzzle; understanding what the model has actually learned is equally, if not more, important. In the next section, we’ll discuss some strategies to mitigate these issues and build models that are both high-performing and reliable.
The Illusion of Performance
When we talk about a machine learning model’s performance, we often refer to metrics like accuracy, precision, recall, 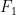
However, these metrics can sometimes create an illusion of performance. A high accuracy rate might make us think that our model is doing an excellent job. But what if the dataset is imbalanced, and the model is simply predicting the majority class for all inputs? In such a case, the model’s high accuracy is misleading. Similarly, a low MSE in a regression model might make us feel confident, but what if the model is overfitting to the training data and performs poorly on new, unseen data?
The point is, while performance metrics are essential, they are not the end-all-be-all of model quality. They give us a snapshot of how well the model is doing on a particular dataset, but they don’t necessarily tell us how well the model will perform in the real world, on new and unseen data. They also don’t tell us anything about whether the model has actually learned the underlying patterns in the data, or if it has simply memorized the training data or found some loophole to exploit.
In the following sections, we’ll explore some of the reasons why a model that appears to perform well might actually be a bad model. We’ll look at the pitfalls of overfitting, the dangers of spurious correlations, and the importance of understanding what the model has actually learned. So let’s dive in and unravel the complexities behind the illusion of performance.
The Problem of Overfitting: When a Model Does Not Generalize
One of the most common pitfalls in machine learning is overfitting. But what exactly is overfitting? In simple terms, overfitting occurs when a model learns the training data too well, capturing not just the underlying patterns but also the noise and random fluctuations. As a result, while the model performs exceptionally well on the training data, it fails to generalize to new, unseen data. In essence, the model becomes a “memorization machine” rather than a “generalization machine.”
Why Overfitting is a Problem
Imagine you’re studying for an exam, and instead of understanding the core principles of the subject, you memorize the answers to all the questions in the textbook. You might score well if the exam questions are identical to those in the book, but you’ll likely perform poorly on questions that require a deep understanding of the subject matter. Similarly, an overfit model performs well on the data it has seen but is likely to make incorrect predictions on new data.
Signs of Overfitting
How can you tell if your model is overfitting? One classic sign is a significant discrepancy between the model’s performance on the training set and its performance on a validation or test set. If your model has a high accuracy on the training set but a much lower accuracy on the validation set, that’s a red flag.
A Simple Example
Let’s consider a simple example using polynomial regression. Suppose you’re trying to fit a model to a set of points that follow a linear trend but also contain some random noise. If you fit a high-degree polynomial to this data, the curve might pass through almost all the points in the training set, resulting in a low MSE. However, this complex model is likely to perform poorly on new data points, as it has essentially “memorized” the noise in the training set.
How to Mitigate These Issues
So far, we’ve discussed various pitfalls that can make a seemingly high-performing machine learning model a bad one. But all is not lost; there are several strategies and best practices you can employ to mitigate these issues. Here’s how:
Cross-Validation
Cross-validation is a powerful technique to assess how well your model will generalize to an independent dataset. By partitioning your original training data into a set of smaller train and test datasets and evaluating performance across all sets, you can get a more reliable estimate of its generalization error.
Regularization
Regularization techniques like L1 or L2 regularization add a penalty term to the loss function, discouraging the model from fitting to the high variance in the training data. This can be particularly useful for preventing overfitting.
Feature Engineering and Selection
Carefully selecting which features to include in your model can go a long way in preventing overfitting and spurious correlations. Domain knowledge is invaluable here, as it allows you to understand which features are likely to have a genuine relationship with the target variable.
Ensemble Methods
Using ensemble methods like Random Forests or Gradient Boosting can improve generalization by combining the predictions of multiple base estimators. This often results in a more robust model that is less likely to overfit or rely on spurious correlations.
Model Interpretability
As we’ve discussed, understanding what your model has learned is crucial. Techniques like LIME or SHAP can provide insights into your model’s decision-making process, helping you identify if it’s taking shortcuts or relying on irrelevant features.
Consult Domain Experts
Especially in fields like healthcare, finance, or any other specialized area, consulting with domain experts can provide invaluable insights. They can help identify whether the features you’re considering are genuinely relevant or if you’re missing critical variables that could improve your model’s performance and reliability.
Continuous Monitoring
Once deployed, continuous monitoring of your model’s performance can help you quickly identify any issues or declines in performance, allowing for timely updates or interventions.
By employing these strategies, you can build machine learning models that are not just high-performing but also robust and reliable. Remember, a good model is not just about high performance metrics; it’s about understanding what the model has learned, how it generalizes to new data, and whether it’s truly capturing the underlying patterns in the data or merely exploiting loopholes and coincidences. In the next section, we’ll wrap up and summarize the key takeaways from this discussion. Stay tuned!
Conclusion
In the rapidly evolving field of machine learning, it’s easy to get caught up in the race for higher performance metrics. While accuracy, precision, and other statistical measures are undoubtedly important, they are just one piece of the puzzle. As we’ve explored in this blog post, a model that appears to perform well may actually be a bad model for various reasons, such as overfitting, exploiting loopholes, or relying on spurious correlations.
The key takeaway is that building a good machine learning model requires a holistic approach. It’s not just about training a model to achieve the highest possible score on some metric; it’s about understanding what the model has actually learned, how well it generalizes to new data, and whether it’s capturing meaningful relationships in the data. Employing strategies like cross-validation, regularization, feature selection, and model interpretability can go a long way in ensuring that your model is both high-performing and robust.
So the next time you find yourself marveling at the performance metrics of your latest model, take a step back and consider the bigger picture. Dive deeper into the model’s behavior, consult with domain experts, and most importantly, validate on unseen data. Remember, a truly good model is one that performs well not just on your training data, but in the real world.
Take the Free Data Maturity Quiz and a Free Consultation
In the world of data science, understanding where you stand is the first step towards growth. Are you curious about how data-savvy your company truly is? Do you want to identify areas of improvement and gauge your organization’s data maturity level? If so, I have just the tool for you.
Introducing the Data Maturity Quiz:
- Quick and Easy: With just 14 questions, you can complete the quiz in less than 9 minutes.
- Comprehensive Assessment: Get a holistic view of your company’s data maturity. Understand the strengths and areas that need attention.
- Detailed Insights: Receive a free score for each of the four essential data maturity elements. This will provide a clear picture of where your organization excels and where there’s room for growth.
Taking the leap towards becoming a truly data-driven organization requires introspection. It’s about understanding your current capabilities, recognizing areas of improvement, and then charting a path forward. This quiz is designed to provide you with those insights.
Ready to embark on this journey?
Take the Data Maturity Quiz Now!
Remember, knowledge is power. By understanding where you stand today, you can make informed decisions for a brighter, data-driven tomorrow.
Free Consultation book a 1-hour consultation for free!